The Audit I Didn’t Write
I have been putting off a proper security audit of Aether for months. It is the kind of work I know I should do, but it is tedious, slow, and I never feel sure I covered everything. So when Anthropic shipped dynamic workflows in Claude Code, I decided to throw the audit at it and see what happened.
This is not a tutorial. It is a report of what I actually ran, what it did, and where I stopped trusting it.
What dynamic workflows actually are
The short version: Claude no longer works as a single agent that solves things step by step. It writes its own orchestration script, splits the task into subtasks, and fans them out across many subagents running in parallel inside the same session. Some agents work on the problem. Other agents try to refute what the first ones found. The run keeps iterating until the results converge, and you get back a single answer that has already been cross checked.
That last part is the interesting bit. The verification does not happen in the conversation. It happens outside it, between agents, before anything reaches you.
It is in research preview right now, and the documentation is very clear about one thing: it burns a lot more tokens than a normal Claude Code session. Keep that in mind, it matters later.
The setup
Aether is a TypeScript monorepo on Node. The audit covered the Aether Server and the CLI. I did not touch the deploy action, I wanted a contained blast radius for a first run.
I gave Claude access to the repo through the CLI and described the goal: a full hardening pass. Input validation across the API surface, auth and session handling, unsafe patterns, and dependency risk. Then I let it plan the workflow on its own instead of scripting the subtasks myself.

The first thing it showed me was the plan: what it was about to run and roughly how many agents. That confirmation step is important, because once you approve it, the thing goes wide fast.
What it did
It broke the codebase into zones and assigned agents per zone. Roughly:
- Input validation across every route handler and the CLI argument parsing.
- Auth and token handling in the Server, including how sessions were created and expired.
- A pass for unsafe patterns: places where user input reached
child_process, dynamicrequire, unvalidated path joins, that kind of thing. - A dependency review against the
package.jsontree.
What surprised me was the second layer. After the first agents produced findings, other agents went in to challenge them. A flagged issue would get a counter agent asking “is this actually reachable, or is it dead code?” Findings that could not survive that round got dropped before I ever saw them.
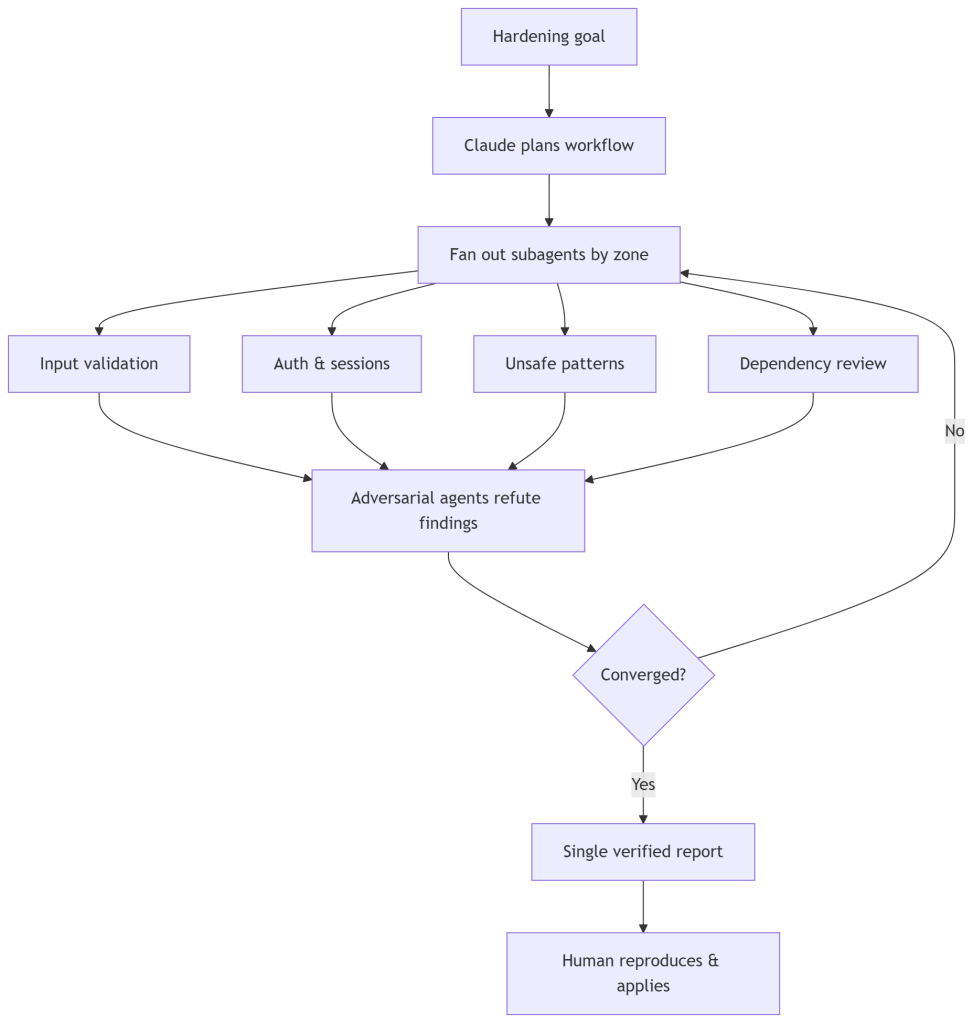
The output was a report with the real issues separated from the noise. Not a wall of low confidence warnings like a typical static analysis run. A short list of things that were actually exploitable in context.
A few examples of what it caught:
// flagged: user-controlled path reaching the filesystemconst file = path.join(BASE_DIR, req.params.name);fs.readFile(file, (err, data) => { /* ... */ });
It correctly traced that req.params.name was never validated and could walk out of BASE_DIR with a ../ payload. The fix it proposed was a resolve-and-check against the base directory, which is the right move:
const resolved = path.resolve(BASE_DIR, req.params.name);if (!resolved.startsWith(BASE_DIR + path.sep)) { return res.status(400).send("invalid path");}
It also flagged a couple of dependencies with known advisories and one place where an error object was being sent back to the client with the full stack, which leaks internal paths.
I reproduced two of the findings by hand before trusting anything. They were real. I applied almost all of the changes with very little editing.
Where it gets uncomfortable
This is the part I keep coming back to.
A security audit is not boilerplate. It is exactly the kind of work where experience was supposed to matter, where the value came from having watched things break in production for years. It felt like safe ground. And a script that the model wrote for itself did it well, while I watched logs scroll by.
I have two real problems with the experience, and neither is about whether it worked.
The first is control. When a single agent solves something, you can still follow its reasoning line by line. When a hundred agents work in parallel and argue with each other, you are not reviewing work anymore, you are trusting a verdict. The verification was done by the system, not by me. I accepted the report because it matched my intuition, not because I audited it properly. Which raises the obvious question: who audits the auditor?
The second is cost, and I do not just mean tokens, although yes, the bill is real and noticeably higher than a normal session. The cost that bothers me is different. If I keep handing off the hard tasks, the ones that used to force me to think, what criteria will I have left the day the model is wrong and gives me a clean report anyway? Because it will be wrong eventually. Only now it will be wrong in parallel, a hundred times, with a tidy summary at the end.
What I would actually do with it
To be fair, the tool earns its place for a specific shape of work. Wide, parallelizable, verifiable. A security sweep fits that perfectly, and so do large migrations or dead code hunts across a big repo. For a scoped, well defined audit it gave me days back.
What I would not do is run it on something I do not understand well enough to check. The convergence between agents is convincing, and convincing is not the same as correct. So I keep the human verification step even when it slows me down. The day I stop reproducing the findings by hand is the day the clean report starts deciding for me, and I am not ready to hand that over yet.


Leave a comment